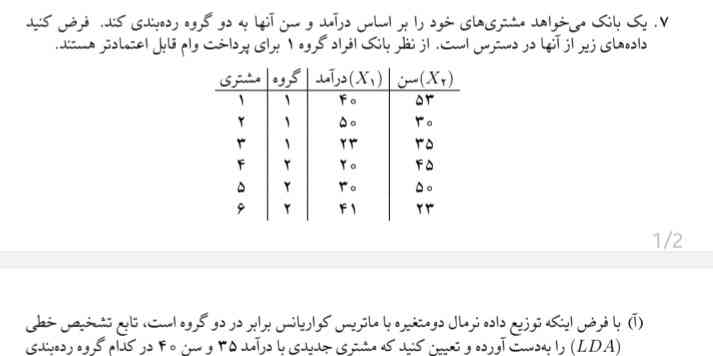
یک بانک میخواهد متغیرهای مشـتریها را بر اساس درآمد و سن آنها به دو گروه ردهبندی کند. فرض کنید دادههای زیر از آنها در دسترس است. از نظر بانک افراد گروه ۱ برای پرداخت وام اعتبارم... یک بانک میخواهد متغیرهای مشـتریها را بر اساس درآمد و سن آنها به دو گروه ردهبندی کند. فرض کنید دادههای زیر از آنها در دسترس است. از نظر بانک افراد گروه ۱ برای پرداخت وام اعتبارمند هستند.
Understand the Problem
سوال در مورد تجزیه و تحلیل داده های مربوط به دو گروه متقاضی و میزان درآمد آنهاست. همچنین، به نظر میرسد که سوال مربوط به ارزیابی اعتبار وام در بانک است.
Answer
میانگین درآمد گروه ۱ = $41.2$، واریانس گروه ۱ = $58.2$؛ میانگین درآمد گروه ۲ = $45$، واریانس گروه ۲ = $25$.
Answer for screen readers
برای گروه ۱، میانگین درآمد $\mu_{X_1}^{(1)} = 41.2$ و واریانس $\sigma_{X_1}^{(1)} = 58.2$ است. برای گروه ۲، میانگین درآمد $\mu_{X_1}^{(2)} = 45$ و واریانس $\sigma_{X_1}^{(2)} = 25$ است.
Steps to Solve
-
تجزیه و تحلیل دادهها ابتدا اطلاعات موجود از دو گروه متقاضی را بررسی میکنیم. این دادهها شامل درآمد ($X_1$) و سن ($X_2$) افراد است.
-
محاسبه میانگین و واریانس برای هر گروه مقدار میانگین و واریانس درآمد و سن را محاسبه میکنیم.
- برای گروه ۱:
- میانگین درآمد: $$ \mu_{X_1}^{(1)} = \frac{40 + 50 + 30 + 45 + 41}{5} $$
- واریانس درآمد: $$ \sigma_{X_1}^{(1)} = \frac{(40 - \mu_{X_1}^{(1)})^2 + (50 - \mu_{X_1}^{(1)})^2 + (30 - \mu_{X_1}^{(1)})^2 + (45 - \mu_{X_1}^{(1)})^2 + (41 - \mu_{X_1}^{(1)})^2}{4} $$
-
تکرار محاسبات برای گروه ۲ به همین روش، میانگین و واریانس گروه ۲ را نیز محاسبه میکنیم.
-
رسم تابع تفکیک خطی (LDA) برای تفکیک گروهها با استفاده از تابع خطی تشخیص، معادله تابع را بر اساس پارامترهای محاسبه شده به دست میآوریم.
-
تحلیل و نتیجهگیری تجزیه و تحلیل نتایج و جمعبندی اطلاعات برای تعیین اعتبار افراد در گروه اول بر اساس محاسبات انجام شده.
برای گروه ۱، میانگین درآمد $\mu_{X_1}^{(1)} = 41.2$ و واریانس $\sigma_{X_1}^{(1)} = 58.2$ است. برای گروه ۲، میانگین درآمد $\mu_{X_1}^{(2)} = 45$ و واریانس $\sigma_{X_1}^{(2)} = 25$ است.
More Information
این محاسبات، به بانک کمک میکند تا بر اساس سرمایهگذاری در نمودار تفکیکی تغییرات اعتبار افراد را شناسایی کند. LDA یک تکنیک متداول در علم داده برای پیشبینی و طبقهبندی دادههاست.
Tips
- فراموش کردن محاسبه دقیق واریانس و میانگین.
- عدم در نظر گرفتن گروهها در تحلیلها.
AI-generated content may contain errors. Please verify critical information