Podcast
Questions and Answers
In the context of multivariate OLS, under what specific condition does including additional control variables fail to mitigate endogeneity, subsequently leading to potentially spurious causal inferences, assuming all OLS assumptions generally hold?
In the context of multivariate OLS, under what specific condition does including additional control variables fail to mitigate endogeneity, subsequently leading to potentially spurious causal inferences, assuming all OLS assumptions generally hold?
- When the added control variables exhibit perfect multicollinearity with the primary independent variable, rendering individual coefficient estimates indeterminate.
- When the control variables are *consequences* of the dependent variable; this introduces reverse causality, exacerbating endogeneity.
- When the control variables are measured with substantial error, undermining their capacity to serve as effective proxies for underlying confounders.
- When the control variables are only weakly correlated with *both* the independent variable *and* the dependent variable, thus contributing minimal information for bias reduction. (correct)
Suppose a researcher omits a salient variable, $Z$, from a regression model predicting $Y$ based on $X$. Under what precise circumstances would the omission of $Z$ not induce omitted variable bias in the estimated coefficient for $X$?
Suppose a researcher omits a salient variable, $Z$, from a regression model predicting $Y$ based on $X$. Under what precise circumstances would the omission of $Z$ not induce omitted variable bias in the estimated coefficient for $X$?
- When $Z$ is highly correlated with $Y$ but entirely uncorrelated with $X$, thus representing an exogenous shift in the dependent variable.
- When $Z$ is a perfect linear combination of the included variable $X$, resulting in multicollinearity, not omitted variable bias.
- When $Z$ is only causally related to another omitted variable $W$, which is correlated with $X$ and $Y$; this only affects the estimate of $W$.
- When $Z$ is uncorrelated with *both* the included regressor $X$ and the dependent variable $Y$; thus, it does not confound their relationship. (correct)
Consider a structural equation where $Y_i = \beta_0 + \beta_1 X_{1i} + \beta_2 X_{2i} + \epsilon_i$, but a researcher mistakenly estimates $Y_i = \beta_0^{OX2} + \beta_1^{OX2} X_{1i} + \epsilon_i$. If $X_{2i} = \delta_0 + \delta_1 X_{1i} + \tau_i$, and (\tau_i) is uncorrelated with (\nu_i) and (X_1), what is the precise mathematical expression for the omitted variable bias in the estimator (\beta_1^{OX2})?
Consider a structural equation where $Y_i = \beta_0 + \beta_1 X_{1i} + \beta_2 X_{2i} + \epsilon_i$, but a researcher mistakenly estimates $Y_i = \beta_0^{OX2} + \beta_1^{OX2} X_{1i} + \epsilon_i$. If $X_{2i} = \delta_0 + \delta_1 X_{1i} + \tau_i$, and (\tau_i) is uncorrelated with (\nu_i) and (X_1), what is the precise mathematical expression for the omitted variable bias in the estimator (\beta_1^{OX2})?
- \(\beta_1^{OX2} = \beta_1 + \beta_2\delta_1\) (correct)
- \(\beta_1^{OX2} = \beta_1 * \delta_1\)
- \(\beta_1^{OX2} = \beta_1 - \beta_2\delta_1\)
- \(\beta_1^{OX2} = \beta_1 / (1 + \delta_1)\)
In a scenario where (\text{Corr}(X_1, X_2) < 0) and (\beta_2 > 0), what is the most likely direction of the bias introduced when (X_2) is omitted from a regression model attempting to estimate the effect of (X_1) on (Y)?
In a scenario where (\text{Corr}(X_1, X_2) < 0) and (\beta_2 > 0), what is the most likely direction of the bias introduced when (X_2) is omitted from a regression model attempting to estimate the effect of (X_1) on (Y)?
Assume a regression analysis aims to estimate the effect of mileage (mpg) on the price of a car. In a bivariate regression, the coefficient on mpg is -238.9 (significant at p<0.01). After adding 'weight' and 'foreign' (whether the car is foreign-made) as controls in a multivariate regression, the coefficient on mpg becomes 21.85 (insignificant). What is the most rigorous interpretation of this coefficient change, assuming that the multivariate model is correctly specified?
Assume a regression analysis aims to estimate the effect of mileage (mpg) on the price of a car. In a bivariate regression, the coefficient on mpg is -238.9 (significant at p<0.01). After adding 'weight' and 'foreign' (whether the car is foreign-made) as controls in a multivariate regression, the coefficient on mpg becomes 21.85 (insignificant). What is the most rigorous interpretation of this coefficient change, assuming that the multivariate model is correctly specified?
In the context of econometric modeling, under what precise condition will measurement error in the dependent variable lead to biased OLS estimates, assuming standard OLS assumptions (besides the absence of measurement error) are met?
In the context of econometric modeling, under what precise condition will measurement error in the dependent variable lead to biased OLS estimates, assuming standard OLS assumptions (besides the absence of measurement error) are met?
Consider a scenario where the 'true' model is given by $Y_i = \beta_1 X_i^* + \epsilon_i$, but $X_i^$ is unobserved. Instead, we observe $X_i = X_i^ + \nu_i$, where (\nu_i) is a random error term with mean zero and is uncorrelated with both (X_i^*) and (\epsilon_i). What is the technical term for the type of bias that OLS estimation of (Y_i = b_1 X_i + \epsilon_i) will inevitably produce?
Consider a scenario where the 'true' model is given by $Y_i = \beta_1 X_i^* + \epsilon_i$, but $X_i^$ is unobserved. Instead, we observe $X_i = X_i^ + \nu_i$, where (\nu_i) is a random error term with mean zero and is uncorrelated with both (X_i^*) and (\epsilon_i). What is the technical term for the type of bias that OLS estimation of (Y_i = b_1 X_i + \epsilon_i) will inevitably produce?
Given the model $Y_i = \beta_1 X_i^* + \epsilon_i$ and the observation equation $X_i = X_i^* + \nu_i$, where (\nu_i) is uncorrelated with (X_i^*) and (\epsilon_i), what is the probabilistic limit (plim) of the OLS estimator (b_1) in the regression (Y_i = b_1 X_i + \epsilon_i)?
Given the model $Y_i = \beta_1 X_i^* + \epsilon_i$ and the observation equation $X_i = X_i^* + \nu_i$, where (\nu_i) is uncorrelated with (X_i^*) and (\epsilon_i), what is the probabilistic limit (plim) of the OLS estimator (b_1) in the regression (Y_i = b_1 X_i + \epsilon_i)?
Assume X and Y are independent random variables. Which of the following statements accurately describes their covariance?
Assume X and Y are independent random variables. Which of the following statements accurately describes their covariance?
Given random variables A, B, W, Z and constants a, b, e, d, which of the following represents the correct expansion of $cov(aA + bB, eW + dZ)$?
Given random variables A, B, W, Z and constants a, b, e, d, which of the following represents the correct expansion of $cov(aA + bB, eW + dZ)$?
Let X and Y be random variables. Under what specific condition is $var(X + Y) = var(X) + var(Y)$?
Let X and Y be random variables. Under what specific condition is $var(X + Y) = var(X) + var(Y)$?
A researcher posits the model $Y_i = \beta_1 X_i^* + \epsilon_i$, where $X_i^$ represents the 'true' value of an independent variable and (\epsilon_i) is an error term. However, $X_i^$ is measured with error, such that the observed value is $X_i = X_i^* + \nu_i$, where (\nu_i) is a purely random measurement error, independent of (X_i^) and (\epsilon_i). The researcher estimates the misspecified model, $Y_i = b_1 X_i + e_i$. If (\text{var}(X^)= 5) and (\text{var}(\nu) = 2 ), by what approximate percentage will the OLS estimate (b_1) be attenuated compared to the 'true' (\beta_1)?
A researcher posits the model $Y_i = \beta_1 X_i^* + \epsilon_i$, where $X_i^$ represents the 'true' value of an independent variable and (\epsilon_i) is an error term. However, $X_i^$ is measured with error, such that the observed value is $X_i = X_i^* + \nu_i$, where (\nu_i) is a purely random measurement error, independent of (X_i^) and (\epsilon_i). The researcher estimates the misspecified model, $Y_i = b_1 X_i + e_i$. If (\text{var}(X^)= 5) and (\text{var}(\nu) = 2 ), by what approximate percentage will the OLS estimate (b_1) be attenuated compared to the 'true' (\beta_1)?
Consider a scenario where data on individual incomes are collected using a survey. Respondents are asked to self-report their annual income, but some individuals intentionally overstate or understate their income due to privacy concerns or social desirability bias. If this misreporting is correlated with individuals' education levels (i.e., more educated individuals tend to underreport income to avoid appearing boastful), what is the likely consequence for a regression analysis attempting to estimate the relationship between education and income?
Consider a scenario where data on individual incomes are collected using a survey. Respondents are asked to self-report their annual income, but some individuals intentionally overstate or understate their income due to privacy concerns or social desirability bias. If this misreporting is correlated with individuals' education levels (i.e., more educated individuals tend to underreport income to avoid appearing boastful), what is the likely consequence for a regression analysis attempting to estimate the relationship between education and income?
A researcher is using OLS regression to estimate the returns to schooling. However, the researcher suspects that individuals may systematically misreport their years of education completed. Specifically, individuals with lower cognitive abilities tend to overstate their educational attainment, while those with higher cognitive abilities tend to report it accurately. This misreporting is also correlated with their future earnings. What is the most likely consequence of this non-random measurement error on the estimated return to schooling?
A researcher is using OLS regression to estimate the returns to schooling. However, the researcher suspects that individuals may systematically misreport their years of education completed. Specifically, individuals with lower cognitive abilities tend to overstate their educational attainment, while those with higher cognitive abilities tend to report it accurately. This misreporting is also correlated with their future earnings. What is the most likely consequence of this non-random measurement error on the estimated return to schooling?
A researcher is modeling the relationship between neighborhood socioeconomic status (SES) and student test scores. However, SES is difficult to measure directly, so the researcher uses median household income as a proxy. Suppose that median household income is an imperfect measure of SES because it doesn't capture wealth inequality within the neighborhood. Furthermore, neighborhoods with high wealth inequality tend to have lower average test scores due to social stratification. What is the nature of the endogeneity that this measurement error introduces?
A researcher is modeling the relationship between neighborhood socioeconomic status (SES) and student test scores. However, SES is difficult to measure directly, so the researcher uses median household income as a proxy. Suppose that median household income is an imperfect measure of SES because it doesn't capture wealth inequality within the neighborhood. Furthermore, neighborhoods with high wealth inequality tend to have lower average test scores due to social stratification. What is the nature of the endogeneity that this measurement error introduces?
Researchers are analyzing the effect of air pollution ($X$) on respiratory health outcomes ($Y$) using observational data. Ideally, they would measure individual-level exposure to pollutants using personal air quality monitors. However, due to cost constraints, they rely on publicly available data from regional air quality monitoring stations. These stations provide aggregate pollution levels for large geographic areas, leading to measurement error as they don't capture individual-level variation in exposure. If individuals living closer to major roadways experience systematically higher pollution exposure than captured by the regional monitors while also experiencing worse respiratory health due to other confounding factors, what is the most likely consequence for the estimated effect of air pollution on respiratory health?
Researchers are analyzing the effect of air pollution ($X$) on respiratory health outcomes ($Y$) using observational data. Ideally, they would measure individual-level exposure to pollutants using personal air quality monitors. However, due to cost constraints, they rely on publicly available data from regional air quality monitoring stations. These stations provide aggregate pollution levels for large geographic areas, leading to measurement error as they don't capture individual-level variation in exposure. If individuals living closer to major roadways experience systematically higher pollution exposure than captured by the regional monitors while also experiencing worse respiratory health due to other confounding factors, what is the most likely consequence for the estimated effect of air pollution on respiratory health?
Suppose you are estimating the effect of parental income on children's educational attainment. However, parental income is often underreported in surveys, particularly by high-income individuals seeking to avoid scrutiny. What type of bias does this measurement error most directly introduce, and how would you expect this bias to affect your estimated coefficient on parental income?
Suppose you are estimating the effect of parental income on children's educational attainment. However, parental income is often underreported in surveys, particularly by high-income individuals seeking to avoid scrutiny. What type of bias does this measurement error most directly introduce, and how would you expect this bias to affect your estimated coefficient on parental income?
A researcher wants to study the effect of education on wages, but finds that educational attainment in their survey is top-coded (e.g., all individuals with 16 or more years of education are coded as '16'). If individuals with top-coded education levels also tend to have significantly higher unobserved skills that are correlated with wages, what specific problem does this generate, and how will it affect estimates?
A researcher wants to study the effect of education on wages, but finds that educational attainment in their survey is top-coded (e.g., all individuals with 16 or more years of education are coded as '16'). If individuals with top-coded education levels also tend to have significantly higher unobserved skills that are correlated with wages, what specific problem does this generate, and how will it affect estimates?
A researcher wants to estimate the causal effect of exercise ($X$) on weight loss ($Y$). However, individuals self-report their exercise habits, leading to potential measurement error. Specifically, individuals who are more self-conscious about their weight might overestimate their exercise levels (social desirability bias). If these same individuals also tend to weigh more, how does this non-random measurement error affect the estimated causal effect of exercise on weight loss?
A researcher wants to estimate the causal effect of exercise ($X$) on weight loss ($Y$). However, individuals self-report their exercise habits, leading to potential measurement error. Specifically, individuals who are more self-conscious about their weight might overestimate their exercise levels (social desirability bias). If these same individuals also tend to weigh more, how does this non-random measurement error affect the estimated causal effect of exercise on weight loss?
In a randomized controlled trial (RCT) designed to measure the impact of a new educational intervention on student test scores, researchers discover that some students randomly assigned to the treatment group did not fully comply with the intervention protocol (e.g., they attended only a fraction of the tutoring sessions). How does this imperfect compliance affect the estimated intent-to-treat (ITT) effect, and how does it relate to attenuation bias?
In a randomized controlled trial (RCT) designed to measure the impact of a new educational intervention on student test scores, researchers discover that some students randomly assigned to the treatment group did not fully comply with the intervention protocol (e.g., they attended only a fraction of the tutoring sessions). How does this imperfect compliance affect the estimated intent-to-treat (ITT) effect, and how does it relate to attenuation bias?
A researcher is studying the impact of financial literacy training on household savings. To measure financial literacy, they use a multiple-choice quiz. However, some quiz questions are poorly worded, leading to random guessing and measurement error in the financial literacy scores. If high levels of random guessing are especially prevalent among individuals with lower cognitive abilities, even after the training, what specific consequence is most likely?
A researcher is studying the impact of financial literacy training on household savings. To measure financial literacy, they use a multiple-choice quiz. However, some quiz questions are poorly worded, leading to random guessing and measurement error in the financial literacy scores. If high levels of random guessing are especially prevalent among individuals with lower cognitive abilities, even after the training, what specific consequence is most likely?
A study aims to assess the relationship between neighborhood walkability (X) and residents' physical activity levels (Y). However, walkability is difficult to measure directly, so the researchers use an index based on factors like street connectivity. Suppose residents who are more health-conscious select into more walkable neighborhoods, and these same residents tend to overreport their physical activity levels on surveys (social desirability bias). What issue does this correlation create, and how it does alter estimations?
A study aims to assess the relationship between neighborhood walkability (X) and residents' physical activity levels (Y). However, walkability is difficult to measure directly, so the researchers use an index based on factors like street connectivity. Suppose residents who are more health-conscious select into more walkable neighborhoods, and these same residents tend to overreport their physical activity levels on surveys (social desirability bias). What issue does this correlation create, and how it does alter estimations?
Flashcards
Endogeneity
Endogeneity
A situation where observational data leads to biased or inconsistent estimates in statistical models.
Multivariate OLS
Multivariate OLS
A statistical method used to control for multiple variables, helping to reduce endogeneity and increase precision in causal inference.
Omitted Variable Bias
Omitted Variable Bias
Bias that occurs when a relevant variable is left out of the model, leading to distorted coefficient estimates.
Formula for Omitted Variable Bias
Formula for Omitted Variable Bias
Signup and view all the flashcards
Measurement Error
Measurement Error
Signup and view all the flashcards
Impact of Random Error
Impact of Random Error
Signup and view all the flashcards
Attenuation Bias
Attenuation Bias
Signup and view all the flashcards
Independent (Uncorrelated)
Independent (Uncorrelated)
Signup and view all the flashcards
Covariance of Independent Variables
Covariance of Independent Variables
Signup and view all the flashcards
Study Notes
- ECON 266: Introduction to Econometrics
- Promise Kamanga, Hamilton College, 02/27/2025
- Multivariate OLS
From the Previous Class
- Observational data contains endogeneity.
- Multivariate OLS is a method for controlling for other variables to reduce endogeneity.
- It reduces bias and increases precision when conducting causal inference.
- The equation for the previous class is: Y; = βο + β1X1; + β2X2; + ... + ẞmXmi + ε¡
Omitted Variable Bias
- Thinking about what happens when omitting a relevant variable provides another way to think about how multivariate OLS fights endogeneity
- The true model is given by Y; = βο + β1X1; + β2X2i + v¡
- X₁₁ and v; are independent (uncorrelated)
- If the true model estimates the following model instead: Y₁ = βOX2 + βOX2X1¡ + £¡
- The relationship between X1¡ and X2; is given by: Χ2; = δο + δ1X1; + Τ¡
- It's assumed that T; is uncorrelated with v; and X₁
- Estimating the equation above yields a biased estimated coefficient by following these steps:
- Start with the true model
- Substitute the expression for X2; in it
- Group "like terms"
- The omitted variable bias is given by βOX2 = β1 + β201
- The stronger the relation between X₁ and X2, the stronger the bias.
- The bigger the impact that X2; has on Y, the stronger the bias.
Anticipating the Sign of Omitted Variable Bias
- The effect of the omitted variable on Y may vary depending on the relationship between beta 2, delta 1, Corr(X1, X2).
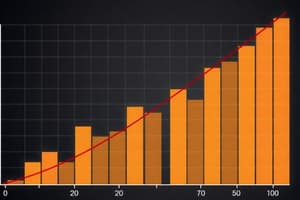
Omitted Variable Bias Example
- Multivariate OLS results, showing the effect of mileage on the price of a car
- Including more variables, the coefficient for MPG reduces.
Measurement Error
- Discussions assume that variables have been measured without error.
- Data can be incorrectly measured for various reasons.
- Incorrect data entry
- People lie in self-reported data
- Errors in formulas to calculate variables
- Quantifying obscure variables
- The effect that measurement error has on data analysis depends on the variable that suffers from it.
- The effect is generally less severe when the error is only in the dependent variable.
- When the error is in the explanatory variable, the end result is a biased estimate.
Measurement Error in the Dependent Variable
- When the measurement error in the dependent variable is random OLS yields:
- Unbiased but less precise estimates
- Reduced R-squared
- When the measurement error in Y is non-random, OLS can yield biased estimates.
Measurement Error in the Independent Variable
- When the measurement error is in the independent variable, the end result is attenuation bias of the estimated coefficient.
- OLS systematically underestimates the magnitude of the coefficient.
- Use a simplified model without the constant term to mathematically derive this outcome.
- Assume the true model is: Y¡ = β₁Χ;* + ε¡
- X* is uncorrelated with ε
- Suppose we not observe X* directly instead we observe some X; that is a function of X* as follows: X₁ = X * + v¡
- v has mean zero and is neither correlated with X* nor with ε
- This means that the model we would estimate would be: Y¡ = β₁X¡ + ε¡
- The estimated coefficient for the model in Equation (3) will have the usual form:
- b= Σ(ΧΥ)/Σ(Χ)²
- In the limit (when N gets really large) plim b= cov(X,Y) / var(X)
- We want to show that: plim b₁= cov(X,Y) / var(X) < β1
- Before that, review some rules about the covariance/variance of random variables.
Rules of Covariance
- X and Y are independent (uncorrelated): cov (X, Y) = 0
- Covariance of a random variable with itself: cov (X, X) = var (X)
- Covariance of linear combinations: cov (aX + bY, cW+dZ) = ac cov (XW) + ad cov (XZ) + eb cov (YW) + bd cov (YZ)
Rules of Variance
- Variance of X and Y: var (X + Y) = var (X) + var (Y) + 2 cov (X, Y)
- When X and Y are independent, var (X + Y) = var (X) + var (Y)
Measurement Error in the Independent Variable
- Applying the previous rules and using the expressions in Equation 1 and Equation 2, we can show that: plim b = cov(X,Y) / var(X) < β1
Studying That Suits You
Use AI to generate personalized quizzes and flashcards to suit your learning preferences.